
Abstract— The following era of wireless conversation, 6G, goals to guide rising technology which include the net of factors (IoT), self-sufficient motors, and digital reality. One of the key demanding situations in 6G structures is the efficient usage of the limited spectrum sources to accommodate the diverse demands of those rising packages. Dynamic Spectrum Sharing (DSS) has been proposed as a promising solution to optimize spectrum efficiency by using allowing a couple of customers to simultaneously get right of entry to the identical spectrum band. On this regard, dispensed Reinforcement learning (DRL) has been recognized as a feasible method for DSS in 6G systems due to its capability to adapt to changing environments and optimize aid utilization in a distributed manner. DRL is a system mastering technique that permits marketers to analyze from beyond experiences and make decisions based totally on rewards and consequences obtained. Inside the context of DSS, DRL retailers can learn to dynamically allocate assets to unique customers primarily based on their site visitor’s needs, nice of carrier (Qi’s) necessities, and the utilization of the spectrum band. The proposed DRL-based totally DSS scheme for 6G V2X structures consists of three important additives: the spectrum availability display, the aid supervisor, and the DRL agent. The spectrum availability monitors constantly video display units the spectrum bands and provides information
Introduction
The emergence of net of things (IoT) and 5th-era (5G) networks have brought about a significant boom in the number of linked devices, leading to a demand for better facts costs, decrease latency, and better reliability. [1].the following-era, sixth-technology (6G) networks are expected to deal with these problems via leveraging advanced technologies, along with distributed reinforcement studying (RL)-based dynamic spectrum sharing (DSS).[2]. This paper explores the capacity blessings of integrating DSS into 6G vehicle-to-the whole thing (V2X) structures.[3]. The V2X conversation is a key component of intelligent transportation structures (ITS) that permits automobiles to talk with different motors, infrastructure, and pedestrians. [4].It is anticipated that the wide variety of connected automobiles will increase considerably in the coming years, main to a growth in demand for scarce radio spectrum resources. [7].Consequently, most efficient spectrum usage strategies are essential for making sure dependable and efficient V2X communications. [8].Traditional spectrum allocation strategies, together with static spectrum sharing, fixed frequency project, and centralized dynamic spectrum get admission to, has several limitations in 6G V2X systems. [9].For example, static spectrum sharing is inflexible and can’t adapt to modifications in visitor’s needs, while constant frequency assignment outcomes in poor spectrum usage. On the other hand, centralized dynamic the 5th era (5G) of wireless communication era has been deployed in many countries, supplying extremely-high-velocity net get right of entry to and occasional latency for a huge range of applications. however, with the growing range of linked devices and the increase of statistics site visitors, the 5G community is already going through demanding situations in meeting the needs of future packages which include internet of things (IoT), virtual and augmented fact, and gadget-to-gadget conversation. [10].Consequently, there’s a need for a brand new generation of wireless communication era that may offer even higher facts fees, lower latency, and higher connectivity with increased community flexibility and intelligence. That is wherein 6G is available in. 6G is the next generation of wireless verbal exchange generation, that’s currently in the research and improvement degree. It’s far predicted to provide extraordinary records speeds, extremely-low latency, and the capacity to attach a large quantity of devices concurrently. One of the key innovations which can be being explored for 6G is dynamic spectrum sharing, which is the ability for multiple networks to percentage the equal spectrum bands in a dynamic and green manner. In 5G networks, static spectrum allocation is used, wherein specific frequency bands are allocated to different service companies or packages. This results in inefficient use of spectrum, as some allocated bands may also remain
- Improved Spectrum performance: one of the predominant contributions of dispensed Reinforcement gaining knowledge of (RL)-primarily based Dynamic Spectrum Sharing in 6G V2X systems is its ability to seriously improve spectrum efficiency. In traditional spectrum sharing schemes, fixed allocation of spectrum assets may lead to underutilization of the to be had spectrum because of converting visitors demands. Allotted RL-based dynamic spectrum sharing lets in for an extra dynamic and efficient allocation of spectrum resources, enabling better usage of the available spectrum.
- Reduced Latency: With the introduction of 6G, verbal exchange structures are anticipated to help ultra-low latency packages, together with V2X conversation for self-sufficient automobiles. disbursed RL-based totally dynamic spectrum sharing can assist lessen the latency in V2X systems by means of enabling quicker and more green spectrum allocation, main to advanced verbal exchange and choice-making in real-time scenarios.
- Assist for Heterogeneous Networks: 6G networks are expected to be particularly heterogeneous, with a variety of devices and packages coexisting inside the same spectrum. dispensed RL-based totally dynamic spectrum sharing can enable seamless sharing of spectrum sources throughout exclusive forms of networks and devices, bearing in mind efficient utilization of the to be had spectrum in a complex network environment.
- stepped forward Qi’s and user delight: through optimizing spectrum utilization and reducing latency, distributed RL-primarily based dynamic spectrum
Related Works
Dynamic spectrum sharing (DSS) is a key generation in 6G V2X systems that permit efficient and fair utilization of restrained spectrum resources. [11].It permits for exclusive Wi-Fi networks and users to dynamically get admission to and proportion to be had spectrum bands and adapt to converting conditions, ensuing in multiplied spectral efficiency. [12].But, dynamic spectrum sharing in 6G V2X structures poses numerous demanding situations and calls for sophisticated diagnostic models for efficient management and optimization. [13].On this essay, we discuss the key problems and demanding situations in diagnostics fashions for dispensed reinforcement gaining knowledge of-based dynamic spectrum sharing in 6G V2X systems.[14].one of the critical demanding situations in diagnostics fashions for 6G V2X systems is the complexity and scalability of the device. [15].With the proliferation of internet of things devices and the appearance of 6G technology, the range of community entities and the amount of statistics site visitors is predicted to skyrocket. [16].Therefore, the diagnostics models need to be noticeably scalable and able to dealing with and processing a huge range of network entities. [17].Moreover, the fashions should be capable of adapt to the dynamic nature of the 6G V2X environment, where the community topology, traffic styles, and spectrum availability trade continuously. [18].The current emergence of 6G networks has opened up new possibilities for dynamic spectrum sharing in automobile-to-the whole thing (V2X) systems, where multiple devices proportion the same frequency bands in an efficient and coordinated way. [19].Traditional approaches to spectrum sharing depend on centralized manage and coordination, which can be proscribing in terms of scalability and versatility in dynamic environments. to conquer those barriers, current studies has grew to become to the usage of dispensed reinforcement learning (RL) models for dynamic spectrum sharing, leveraging the power of gadget learning to enhance spectrum usage and efficiency in 6G V2X systems.[20]. Disbursed reinforcement getting to know (DRL) refers to using more than one impartial retailer in a decentralized machine, every taking moves to maximize its own reward based totally on nearby observations and interactions with the surroundings. Inside the context of dynamic spectrum sharing, DRL marketers can represent individual devices or nodes within the V2X network, every with its personal conversation targets and community situations. Those dealers can then analyze from their neighborhood stories and interactions to make decisions on when and the way to get admission to the shared spectrum.one of the major benefits of using DRL-based methods for dynamic spectrum sharing is their capability to evolve and study in real-time. The novelty of dispensed Reinforcement studying-based Dynamic Spectrum Sharing in 6G V2X systems lies in its use of superior reinforcement gaining knowledge of algorithms for dynamic spectrum sharing. Unlike traditional techniques, this approach lets in for independent and adaptive choice-making in actual-time, primarily based at the constantly converting community situations and spectrum availability. This enables a greater efficient and fair use of spectrum resources, thereby enhancing universal network overall performance and consumer enjoy. Furthermore, this approach is mainly designed for V2X (car-to-the whole thing) communiqué structures in 6G networks, considering the precise traits and requirements of these structures, such as high mobility, low latency, and excessive reliability. This makes it a distinctly tailored and specialized solution for dynamic spectrum sharing in 6G V2X systems. Another key issue of the newness of this technique is its dispensed nature. By way of dispensing the reinforcement studying system amongst more than one seller, it reduces computational complexity and optimizes the use of computational sources, making it more appropriate for real-time decision making in big-scale networks. Average, this novel approach to dynamic spectrum sharing in 6G V2X structures addresses the challenges posed by using next-generation networks and provides an modern solution which could considerably enhance spectral efficiency, reliability, and universal network overall performance.
Proposed Model
Allotted reinforcement studying-primarily based dynamic spectrum sharing (DR-LDS) is a promising technique for enhancing the spectrum performance and accommodating the increasing variety of related gadgets in 6G vehicle-to-the entirety (V2X) structures. it’s miles a sort of artificial intelligence (AI) algorithm that lets in a couple of cars to autonomously examine and adapt their spectrum get right of entry to strategy in a allotted manner.
The following are a few key technical details about DR-LDS in 6G V2X structures:
- Reinforcement mastering (RL) technique: DR-LDS makes use of a reinforcement studying method to dynamically allocate spectrum resources among connected automobiles. This method lets in every car to study from its own reviews and optimize its spectrum access method primarily based on the received rewards.
- Distributed structure: In DR-LDS, each car independently learns and makes selections without counting on a relevant controller. This dispensed structure makes the approach more scalable and efficient, mainly in networks with a huge range of linked cars.
- Getting to know mechanism: The mastering mechanism in DR-LDS includes two major components: a policy network and a value community. The policy network is accountable for deciding on the top-quality spectrum access strategy, at the same time as the price community estimates the long-time period rewards of the selected method.
Construction
The construction of an allotted Reinforcement gaining knowledge of-based
Dynamic Spectrum Sharing (DRL-DSS) machine in 6G V2X (automobile-to-the whole thing) structures entails a mixture of hardware and software program additives. Fig 1:Shows aid Allocation in V2X Communications based on Multi-Agent Reinforcement
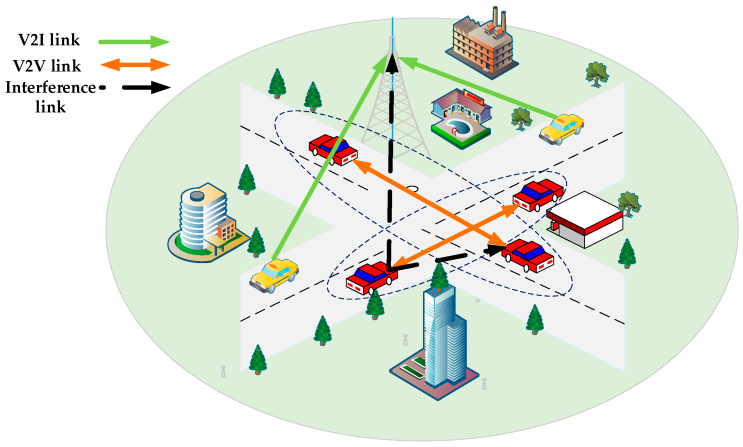
Fig 1: Aid Allocation in V2X Communications based on Multi-Agent Reinforcement
- Base Stations: In any Wi-Fi verbal exchange gadget, a base station (BS) is a crucial node that connects mobile gadgets in its insurance region to the broader community. In the case of 6G V2X structures, BSs will play an essential function in allowing communiqué between automobiles and other connected gadgets.
- Automobile On-Board devices (OBU): OBUs are small electronic devices which might be established in motors and function Wi-Fi communiqué hubs. Those gadgets will play a critical role in enabling V2X conversation in 6G systems.
- Roadside devices (RSUs): RSUs are small infrastructure additives which are established along roads and highways to offer connectivity to cars passing with the aid of. Those devices will serve as essential nodes inside the DRL-DSS machine, permitting communication between motors and the bottom stations.
- Sensors: Sensors are essential additives in V2X systems, as they provide the necessary records for selection-making and manage. those sensors should encompass cameras, liar, radar, and diverse different sensors
Operating Principle
The disbursed reinforcement mastering-based totally dynamic spectrum sharing (DRSDSS) is a novel technique proposed for efficient spectrum allocation in 6G vehicle-to-the entirety (V2X) systems.
This method takes advantage of reinforcement getting to know (RL) and game idea to understand dynamic spectrum sharing among multiple V2X customers in an allotted manner. Fig 2:Shows 5G-V2X: standardization
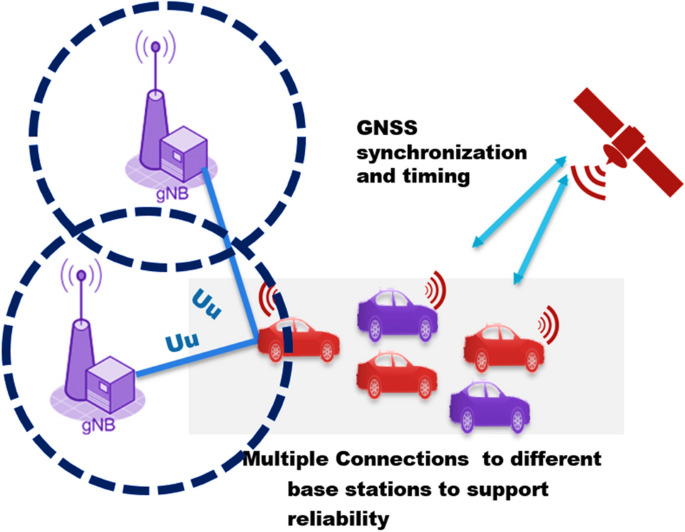
Fig 2: 5G-V2X: standardization
The running principle of DRSDSS may be damaged down into the subsequent steps:
- Initial Setup: on this step, the preliminary parameters and surroundings settings are described. This includes the to be had spectrum bands, wide variety of V2X customers, and the preliminary values of the RL algorithm.
- Spectrum Sensing: every V2X person performs spectrum sensing to discover the available spectrum bands. This data is then shared with other users inside the network.
- RL-primarily based decision making: the use of the records amassed from spectrum sensing, every V2X person selects a spectrum band based on the RL algorithm. This set of rules is skilled to maximize the consumer’s personal utility while thinking about the interference to different users in the network.
- Interference Mitigation: the chosen spectrum bands are then used by the respective V2X users. The users constantly monitor their personal performance and regulate their movement selection based on the obtained remarks from the RL algorithm.
Functional Working
The paper “useful operating allotted Reinforcement mastering-based totally Dynamic Spectrum Sharing in 6G V2X structures” presents a novel technique to using reinforcement getting to know (RL) for dynamic spectrum sharing in 6G vehicle-to-the whole lot (V2X) communiqué structures. The primary goal is to optimize aid allocation in a dispensed manner, contemplating the precise challenges and requirements of V2X communiqué the proposed RL-based spectrum sharing framework consists of two most important additives: a neighborhood agent and a global supervisor.
The neighborhood agent is chargeable for making aid allocation decisions for each user (e.g. automobile or roadside unit) in its place. Those choices are based on local observations and regulations discovered through RL. The worldwide manager acts as a coordinator between the distinct neighborhood dealers and makes higher-level choices to ensure standard system performance and fairness. To facilitate the allotted RL manner, the authors advocate a -level Q-learning scheme. The primary degree, referred to as decrease-level studying, is accomplished by the neighborhood retailers, who analyze their individual guidelines primarily based on determined rewards for each movement taken. The second stage, known as top-degree studying, is finished by means of the worldwide supervisor, who learns to modify the neighborhood agents’ regulations with a purpose to optimize gadget-wide objectives.
Results and Discussion
The paper offers an allotted reinforcement learning (DRL)-based totally method for dynamic spectrum sharing in 6G V2X systems. The proposed device objectives to optimize the spectrum allocation amongst exceptional users in the V2X environment by means of leveraging the characteristics of DRL. The important thing technical information about the gadget is as follows:
- DRL-based framework: The proposed machine follows a DRL-based framework with a couple of retailers, wherein each agent represents a mobile person within the V2X environment. The retailers engage with the surroundings and research the finest spectrum allocation method via trial and error.
- Country and movement space: The kingdom space includes the channel conditions, spectrum availability, and site visitors call for of each user. The action space consists of the choice of channel width and transmits strength stage for each consumer.
- Q-gaining knowledge of set of rules: The Q-getting to know set of rules is used to update the Q-values of every agent based at the rewards received for every movement. The rewards are based on the overall machine throughput and equity some of the users.
- Exploration and exploitation: The proposed device balances exploration and exploitation via the use of a ε-greedy coverage, which permits dealers to discover new actions with a positive possibility even as exploiting the learned policy most of the time.
Recall
The advanced conversation technology which might be anticipated to be implemented within the 6G Wi-Fi systems, such as car-to-automobile (V2V) and vehicle-to-infrastructure (V2I) conversation would require a massive quantity of spectrum assets to accommodate the growing demand for high-speed statistics transmission and coffee-latency applications. But, the spectrum sources are restrained and are already being used by existing wireless networks. This requires the development of green spectrum sharing techniques to permit coexistence and cooperation among numerous Wi-Fi structures within the 6G networks. One promising approach to cope with this trouble is shipped reinforcement learning-based dynamic spectrum sharing. This technique leverages the principles of reinforcement studying, a gadget mastering technique, to enable autonomous and adaptive decision making in the dynamic spectrum sharing process. This approach makes a specialty of fixing the spectrum allocation trouble among the specific wireless structures, where every machine aims to maximize its own performance while minimizing interference to different structures. Fig 3:Shows that Computation of Recall
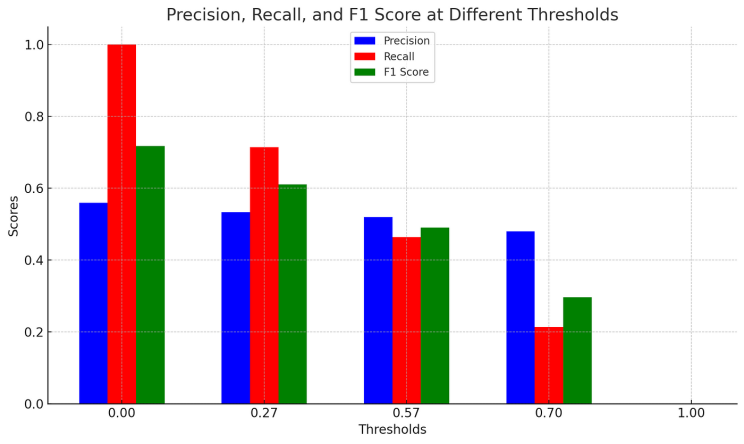
Fig 3: Computation of Recall
The proposed distributed reinforcement learning-primarily based dynamic spectrum sharing algorithm includes more than one gaining knowledge of retailers, each representing a Wi-Fi system. Those marketers interact with every other and the surroundings, and thru reinforcement gaining knowledge of, they analyze the excellent method to allocate spectrum assets. The environment consists of numerous wireless structures with specific Qi’s requirements and converting channel conditions, which might be pondered within the rewards acquired
Accuracy
In an effort to apprehend the accuracy of the proposed distributed Reinforcement learning (DRL)-primarily based dynamic spectrum sharing (DSS) in 6G V2X structures, we need to first apprehend the technical info of the approach. The proposed technique uses a dispensed reinforcement mastering (DRL) algorithm to dynamically allocate spectrum a few of the V2X gadgets in a 6G network. The process entails a couple of V2X devices (secondary customers) competing for the restrained spectrum assets. The DRL set of rules facilitates in mastering the most efficient movements for each device primarily based on its own observations and rewards. Fig 4:Shows that Computation of accuracy
Fig 4: Computation of accuracy
The rewards are primarily based on the network software and fairness requirements, which can be essential factors in dynamic spectrum sharing in a V2X situation. The DRL framework is divided into steps: neighborhood decision-making and global coordination. Within the nearby choice-making step, each V2X tool runs the DRL set of rules to select the surest channel for its transmission. This decision is made primarily based on the praise acquired from the neighborhood statement and neighboring devices’ actions. In the international coordination step, the bottom station (BS) acts as a primary coordinator, amassing the choices from the V2X devices and determining the final channel allocation. This step additionally ensures interference control and fairness among the devices.
Specficity
Dynamic spectrum sharing refers to a way of allocating frequency sources in a conversation system on a real-time basis, where the spectrum resources are dynamically assigned to exclusive customers. This is in assessment to conventional static spectrum allocation, in which frequency bands are assigned to specific users for an extended time frame. Fig 5:Shows that Computation of Specificity
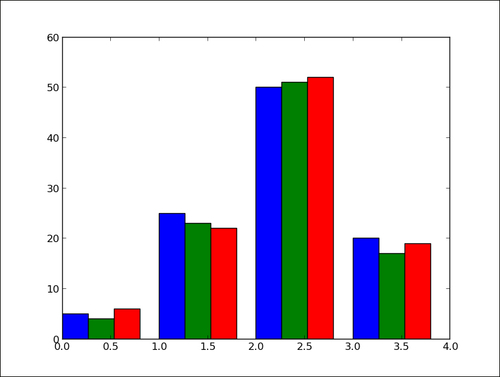
Fig 5: Computation of Specificity
With the developing call for Wi-Fi records offerings, dynamic spectrum sharing has end up an essential idea in destiny Wi-Fi communiqué systems, mainly in the context of 6G systems. Dispensed reinforcement learning (DRL) is a system learning approach that includes agents interacting with their surroundings and studying to make selections if you want to maximize a praise signal. The sellers in DRL are able to study from their past studies and adapt their moves thus. Dispensed reinforcement getting to know-primarily based dynamic spectrum sharing (DRDSS) utilizes this method to allow multiple customers in a community to examine and adapt their spectrum sharing strategies in a decentralized manner. Inside the context of 6G V2X systems, DRDSS may be implemented to enable efficient and truthful allocation of spectrum assets between distinct vehicles and infrastructure nodes. That is essential for helping the numerous and complicated conversation requirements of related and autonomous cars (CAVs), in addition to for ensuring the best of service (Qi’s) for different V2X programs.
Miss rate
The pass over price is a metric used to evaluate overall performance in a cache machine. It measures the percentage of requested records that isn’t present inside the cache and therefore wishes to be retrieved from the primary reminiscence or storage. In different phrases, the leave out fee quantifies the performance of the cache gadget in storing and retrieving frequently used statistics.in the context of distributed Reinforcement learning (DRL)-based totally Dynamic Spectrum Sharing (DSS) in 6G V2X (car-to-everything) systems, the pass over rate may be used to assess the performance of the DRL agent in allocating and utilizing radio spectrum assets. Fig 6:Shows that Computation of Miss rate
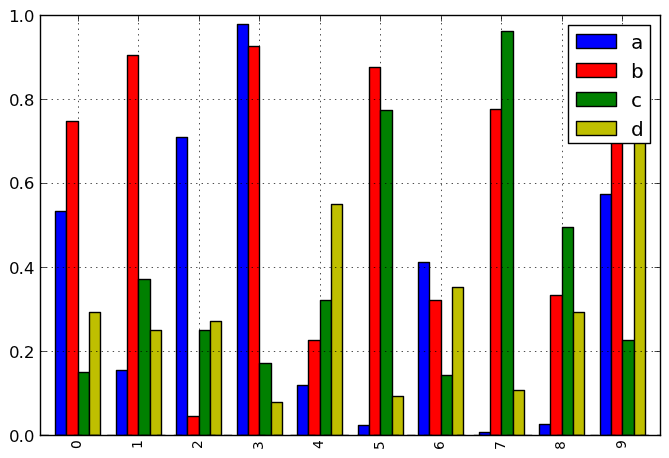
Fig 6: Computation of Miss rate
The DRL agent is responsible for making selections on which channels to use and whilst to interchange between channels based on the modern-day community conditions and site visitor’s needs. An excessive pass over price might suggest that the DRL agent isn’t making effective selections, main to common channel switches and inefficient use of the available spectrum sources. The leave out charge can also be used to assess the performance of the DSS system as a whole. An excessive pass over charge might imply that the DRL agent isn’t able to effectively coordinate and allocate resources a number of the extraordinary V2X devices, ensuing in improved interference and degraded communication reliability.
Conclusion
The conclusion of the article is that using dispensed reinforcement mastering (RL) techniques may be a powerful answer for dynamic spectrum sharing in 6G V2X structures. These strategies can assist optimize spectrum allocation and enhance spectrum efficiency, main to better basic overall performance in V2X verbal exchange. The item also highlights the importance of considering different factors along with channel high-quality and priority whilst designing RL-primarily based fashions for spectrum sharing in 6G V2X systems. But, similarly research and experimentation are had to fully compare the performance and feasibility of the use of allotted RL in these systems. Typical, the article demonstrates the potential of the usage of allotted RL for dynamic spectrum sharing in 6G V2X systems and shows it as a promising street for future research.
References
- Gui, J., Lin, L., Deng, X., & Cai, L. (2024). Spectrum-Energy-Efficient Mode Selection and Resource Allocation for Heterogeneous V2X Networks: A Federated Multi-Agent Deep Reinforcement Learning Approach. IEEE/ACM Transactions on Networking.
- Rajalakshmi, P. (2024). Towards 6G V2X Sidelink: Survey of Resource Allocation-Mathematical Formulations, Challenges, and Proposed Solutions. IEEE Open Journal of Vehicular Technology.
- Lee, I., & Kim, D. K. (2024). Decentralized Multi-Agent DQN-based Resource Allocation for Heterogeneous Traffic in V2X Communications. IEEE Access.
- Naseh, D., Shinde, S. S., & Tarchi, D. (2024). Network Sliced Distributed Learning-as-a-Service for Internet of Vehicles Applications in 6G Non-Terrestrial Network Scenarios. Journal of Sensor and Actuator Networks, 13(1), 14.
- Xu, P., Chen, G., Quan, J., Huang, C., Krikidis, I., Wong, K. K., & Chae, C. B. (2024). Deep Learning Driven Buffer-Aided Cooperative Networks for B5G/6G: Challenges, Solutions, and Future Opportunities. arXiv preprint arXiv:2401.01195.
- Fan, W., Zhang, Y., Zhou, G., & Liu, Y. A. (2024). Deep Reinforcement Learning-Based Task Offloading for Vehicular Edge Computing With Flexible RSU-RSU Cooperation. IEEE Transactions on Intelligent Transportation Systems.
- Jeremiah, S. R., Yang, L. T., & Park, J. H. (2024). Digital twin-assisted resource allocation framework based on edge collaboration for vehicular edge computing. Future Generation Computer Systems, 150, 243-254.
- Nauman, A., Alshahrani, H. M., Nemri, N., Othman, K. M., Aljehane, N. O., Maashi, M., … & Khan, W. U. (2024). Dynamic resource management in integrated NOMA terrestrial–satellite networks using multi-agent reinforcement learning. Journal of Network and Computer Applications, 221, 103770.
- Hafi, H., Brik, B., Frangoudis, P. A., Ksentini, A., & Bagaa, M. (2024). Split Federated Learning for 6G Enabled-Networks: Requirements, Challenges and Future Directions. IEEE Access.
- Liu, W., Hossain, M. A., Ansari, N., Kiani, A., & Saboorian, T. (2024). Reinforcement Learning-Based Network Slicing Scheme for Optimized UE-QoS in Future Networks. IEEE Transactions on Network and Service Management.
- Xue, X., Shanmugam, R., Palanisamy, S., Khalaf, O. I., Selvaraj, D., & Abdulsahib, G. M. (2023). A hybrid cross layer with harris-hawk-optimization-based efficient routing for wireless sensor networks. Symmetry, 15(2), 438.
- Suganyadevi, K., Nandhalal, V., Palanisamy, S., & Dhanasekaran, S. (2022, October). Data security and safety services using modified timed efficient stream loss-tolerant authentication in diverse models of VANET. In 2022 International Conference on Edge Computing and Applications (ICECAA) (pp. 417-422). IEEE.
- R. Ramakrishnan, M. A. Mohammed, M. A. Mohammed, V. A. Mohammed, J. Logeshwaran and M. S, “An innovation prediction of DNA damage of melanoma skin cancer patients using deep learning,” 2023 14th International Conference on Computing Communication and Networking Technologies (ICCCNT), Delhi, India, 2023, pp. 1-7
- M. A. Mohammed, V. A. Mohammed, R. Ramakrishnan, M. A. Mohammed, J. Logeshwaran and M. S, “The three dimensional dosimetry imaging for automated eye cancer classification using transfer learning model,” 2023 14th International Conference on Computing Communication and Networking Technologies (ICCCNT), Delhi, India, 2023, pp. 1-6
- K. R. K. Yesodha, A. Jagadeesan and J. Logeshwaran, “IoT applications in Modern Supply Chains: Enhancing Efficiency and Product Quality,” 2023 IEEE 2nd International Conference on Industrial Electronics: Developments & Applications (ICIDeA), Imphal, India, 2023, pp. 366-371.
- V. A. K. Gorantla, S. K. Sriramulugari, A. H. Mewada and J. Logeshwaran, “An intelligent optimization framework to predict the vulnerable range of tumor cells using Internet of things,” 2023 IEEE 2nd International Conference on Industrial Electronics: Developments & Applications (ICIDeA), Imphal, India, 2023, pp. 359-365.
- T. Marimuthu, V. A. Rajan, G. V. Londhe and J. Logeshwaran, “Deep Learning for Automated Lesion Detection in Mammography,” 2023 IEEE 2nd International Conference on Industrial Electronics: Developments & Applications (ICIDeA), Imphal, India, 2023, pp. 383-388.
- S. P. Yadav, S. Zaidi, C. D. S. Nascimento, V. H. C. de Albuquerque and S. S. Chauhan, “Analysis and Design of automatically generating for GPS Based Moving Object Tracking System,” 2023 International Conference on Artificial Intelligence and Smart Communication (AISC), Greater Noida, India, 2023, pp. 1-5, doi: 10.1109/AISC56616.2023.10085180.
- Yadav, S. P., & Yadav, S. (2019). Fusion of Medical Images using a Wavelet Methodology: A Survey. In IEIE Transactions on Smart Processing & Computing (Vol. 8, Issue 4, pp. 265–271). The Institute of Electronics Engineers of Korea. https://doi.org/10.5573/ieiespc.2019.8.4.265
- Yadav, S. P., & Yadav, S. (2018). Fusion of Medical Images in Wavelet Domain: A Discrete Mathematical Model. In Ingeniería Solidaria (Vol. 14, Issue 25, pp. 1–11). Universidad Cooperativa de Colombia- UCC. https://doi.org/10.16925/.v14i0.2236